
Your most important page ranks #3 in Google. You've held that position for two years. Last week, a prospect asked ChatGPT which platforms in your category handle their use case — and your product wasn't in the answer. Not ranked lower. Not paraphrased. Absent.
This is not a ranking problem. It is a citation problem. Generative engine optimization — the discipline of making content citable, not just crawlable, across AI platforms — is why they are not the same thing.
The gap is already widening. Google AI Overviews peaked at nearly 25% of all queries in July 2025 before stabilizing around 16% by November, according to Semrush's analysis of over 10 million keywords — and that's one platform's AI layer, not the full picture. AI platforms collectively drove over 1.13 billion referral visits to the top 1,000 domains in June 2025 — up 357% year-over-year — with ChatGPT accounting for more than 80% of that share among those domains, per Similarweb.
Practitioners using citation-tracking tools are finding exactly what the numbers suggest: pages ranked highly in Google are frequently absent from AI citations entirely. The foundational assumption that SEO investment transfers to AI visibility is breaking — quietly, across thousands of searches, while teams wait for clarity that isn't coming.
Brands running generic GEO checklists aren't doing incomplete work. They're building AI visibility on one platform while accumulating a citation gap on the others that compounds silently until a model update makes it visible.
The argument here is specific: GEO is not a unified optimization discipline. ChatGPT, Perplexity, and Google AI Mode use distinct citation logic. A single strategy optimized for one platform will systematically underperform — or actively fail — on the others.
What follows is a platform-specific citation framework — the GEO Content Extraction Framework — and the evidence for why the field needs one.
Why Generative Engine Optimization Is Not SEO — and Why the Analogy Is Dangerous
Generative engine optimization is the practice of making content citable by AI systems — not just visible to search crawlers. It is a distinct discipline from SEO, and the "GEO is the next SEO" framing is doing strategic damage.
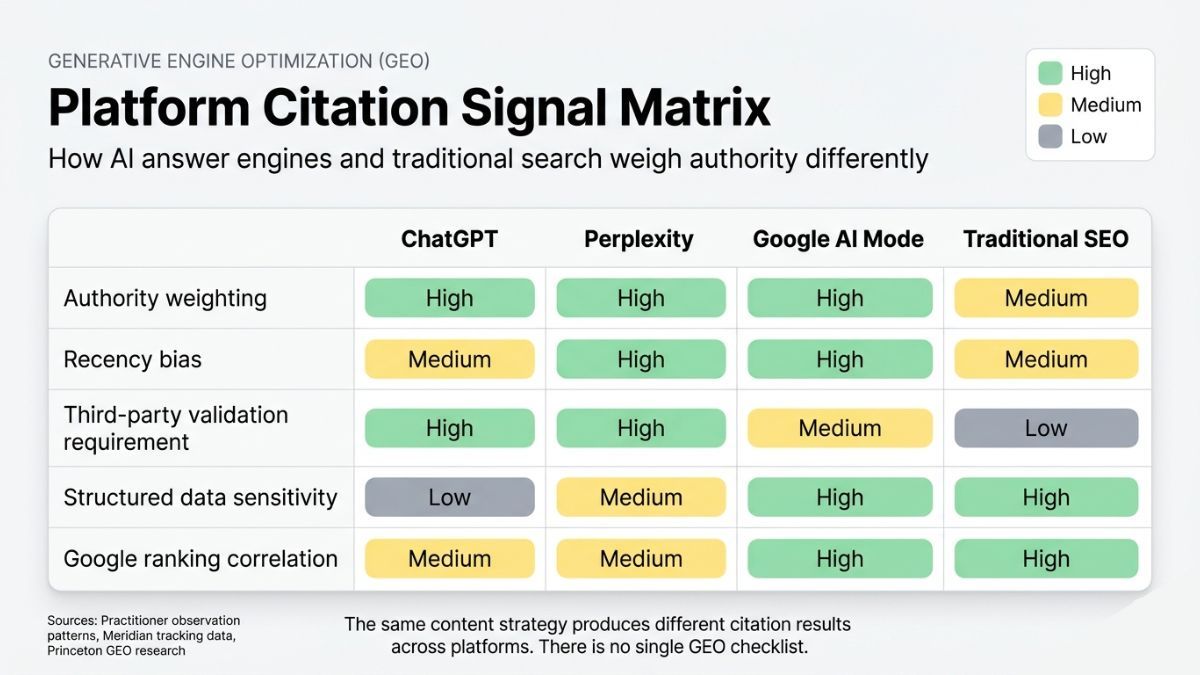
SEO had one algorithm family. A decade of signal analysis produced a coherent optimization logic: authority, relevance, structure, and links. GEO has three major AI platforms with fundamentally distinct retrieval architectures. They weigh authority differently. They treat recency differently. They apply third-party validation requirements differently. The analogy collapses at the system level before it reaches tactics.
Jeffrey Buddle, a marketing strategist who has studied this structural shift, named the distinction precisely: "SEO optimized for visibility. GEO optimizes for selection." Visibility is a surface area problem — show up in more queries. Selection is a trustworthiness problem — be the source a citation-generating system trusts enough to name. The investments required to solve each are not the same.

The dangerous operational implication: teams that accept "GEO is next-gen SEO" build a unified strategy for a fragmented citation environment. They optimize well for one platform and invisibly fail on the others — with nothing in their existing measurement stack signaling it's happening. Traffic data doesn't reveal AI citation gaps. Ranking reports don't capture AI citation presence. The failure accumulates in silence.
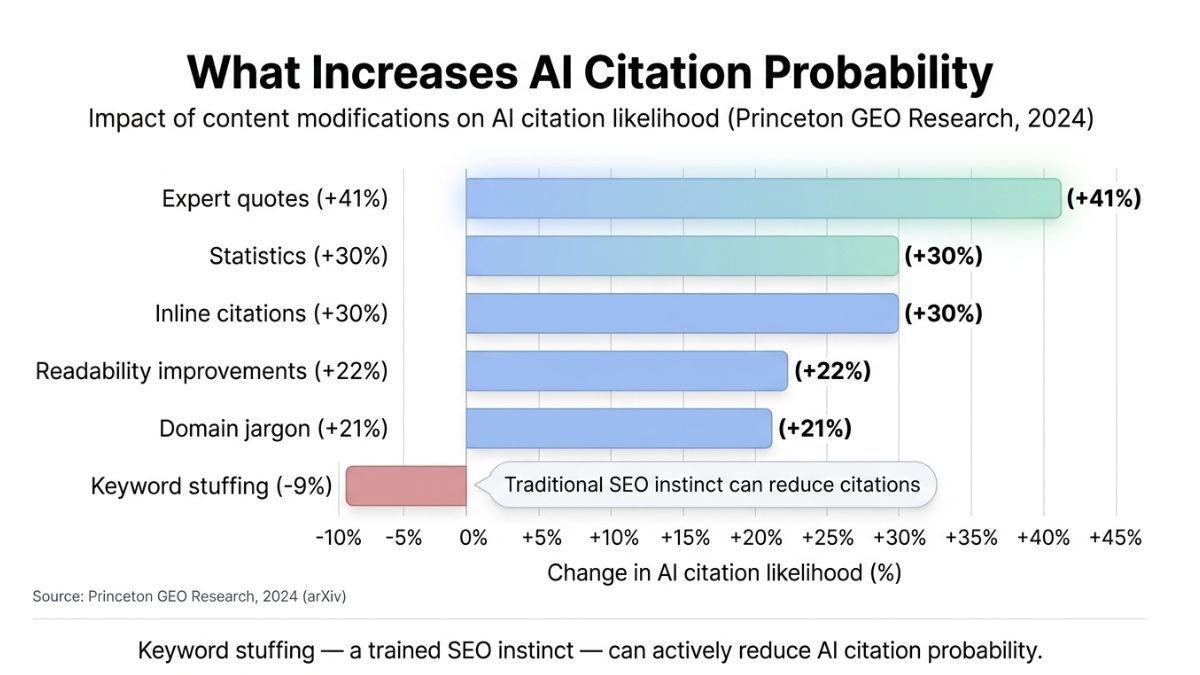
There is also a more specific problem with applying SEO instincts to GEO. Multi-institution research from Princeton, Georgia Tech, The Allen Institute for AI, and IIT Delhi — published as "GEO: Generative Engine Optimization" at KDD 2024 — found that keyword stuffing, a legacy SEO artifact, reduces AI visibility. The optimization habits trained by a decade of search ranking are not neutral in AI citation systems. In some dimensions, they actively work against the goal.
How ChatGPT, Perplexity, and Google AI Mode Cite Differently — and Why You Need a Strategy for Each
A note on evidence before the specifics: the platform-specific citation behavior described here rests on practitioner observation patterns and available cross-platform tracking data, not publicly documented retrieval architecture. These are working models of observed behavior, not confirmed internal specifications. They are directionally consistent with available evidence and should be treated as strategic hypotheses requiring ongoing validation as platforms evolve.
ChatGPT
ChatGPT draws heavily on training data, with real-time browsing as a secondary layer. Citation behavior tends to weight topical authority built through consistent brand presence across multiple sources — not individual page quality. A single well-structured page is insufficient.
ChatGPT's citation logic appears to reward brands that appear consistently across third-party coverage, industry publications, and cross-domain references. To optimize for ChatGPT, the primary lever is brand presence architecture — not page-level formatting. A brand that ranks #1 in Google but appears in few third-party contexts may be structurally underrepresented in ChatGPT answers, regardless of how well those pages are formatted.
Perplexity
Perplexity operates as a real-time retrieval system with a strong recency bias. Pages not indexed in Google can and do get cited if they are structurally extractable and topic-matched — making this the platform where correlation between Google ranking and AI citation appears weakest.
Practitioners running citation tracking have documented this directly: pages performing strongly in Google absent from Perplexity citations, while pages with limited organic presence get cited because they are recent, structured, and precisely on-topic. For Perplexity, recency signals and real-time indexability are the primary optimization levers. Yesterday's authoritative post can lose to this week's precisely structured answer.
Google AI Mode
Google AI Mode (formerly SGE) shows the highest correlation with existing Google rankings of the three platforms. Structured data, E-E-A-T signals, and schema markup carry over more reliably into AI Mode presence — and into Google AI Overviews — than into ChatGPT or Perplexity. This platform most rewards the existing Google optimization stack, but the citation logic remains distinct from ranking logic.
An important structural note: an Ahrefs study found only 13.7% of citations overlap between Google AI Overviews and AI Mode, confirming these are meaningfully different surfaces even within the same platform family. Prompt-level formatting — structuring content so specific passages answer the exact question a prompt would ask — matters more here than on the other two platforms.
The Practical Consequence
Content optimized for Perplexity's recency requirements may not serve the cross-source topical authority signals ChatGPT weights. A Google AI Mode approach built around E-E-A-T may generate no gains on Perplexity for recent queries. The same content, in the same category, on the same day, can be highly cited on one platform and completely absent from another — not because of content quality, but because of platform architecture.
Extractable vs. Citable — The Two Thresholds Most GEO Content Never Crosses
Most GEO advice addresses one threshold. There are two, and the gap between them is where most optimization investment is lost.

Extractable means an AI system can parse and surface a specific passage from the content. This is largely a structural problem: direct answer paragraphs that open with the answer rather than the context, FAQ blocks where each answer is complete without adjacent questions, self-contained claim units that deliver meaning independently. The content architecture makes passage-level retrieval possible. The AI can pull the relevant text.
Citable means an AI system trusts the source enough to attribute it by name. Citation equity — the durable, named presence a brand accumulates across AI-generated answers — cannot be built by structural formatting alone. It requires third-party validation. AI systems appear to cross-reference claims against third-party sources before citing; self-published content alone rarely crosses that threshold.
The distinction explains a pattern practitioners have noticed but struggled to name: content that gets surfaced — extracted as a passage, paraphrased in an answer — but not attributed by brand name or source link. The content crossed the extractable threshold. It didn't cross the citable threshold. No citation equity accumulates from being paraphrased. The brand's presence in the AI answer is invisible to the buyer who sees it.
The "GEO: Generative Engine Optimization" study (Aggarwal et al., KDD 2024 — researchers from Princeton, Georgia Tech, The Allen Institute for AI, and IIT Delhi) quantified the signals most associated with improved visibility: methods involving expert quotes, clear statistics, and inline citations to primary sources each produced 30–40% visibility improvements, with the best-performing individual method achieving a 41% lift on the primary visibility metric. Each operates at the authority signal level, not the structural level — they create cross-referenceable validation, which is the signal AI citation systems appear to use when deciding whether a source is trustworthy enough to surface prominently.
Citation volatility is the strategic consequence of failing to reliably reach the citable threshold. Profound, recognized as a G2 Winter 2026 AEO Leader, reports that clients commonly see citation presence shift significantly after model updates — with no content changes and no warning in traditional ranking reports. The lesson practitioners draw is consistent: structured data helps, but citation equity requires ongoing reinforcement, not one-time optimization.
The SEOeveryday case confirms volatility from the opposite direction. An anonymous practitioner documented the experiment publicly on Reddit in 2024: daily AI-generated articles drove rapid gains in AI Overview and Copilot citations — then collapsed within two to three weeks as Google's systems recognized repetitive sentence structures and low engagement signals. After pivoting to two to three human-edited posts per week, citation positions stabilized. Volume without authority signals is not a compounding strategy.
The GEO Content Extraction Framework — Four Pillars for Durable AI Citation
The framework is not a checklist. It is a layered architecture — each pillar builds on the one before it. Skipping to Pillar 3 without Pillar 2 in place produces the extractable-but-not-citable failure pattern described above.
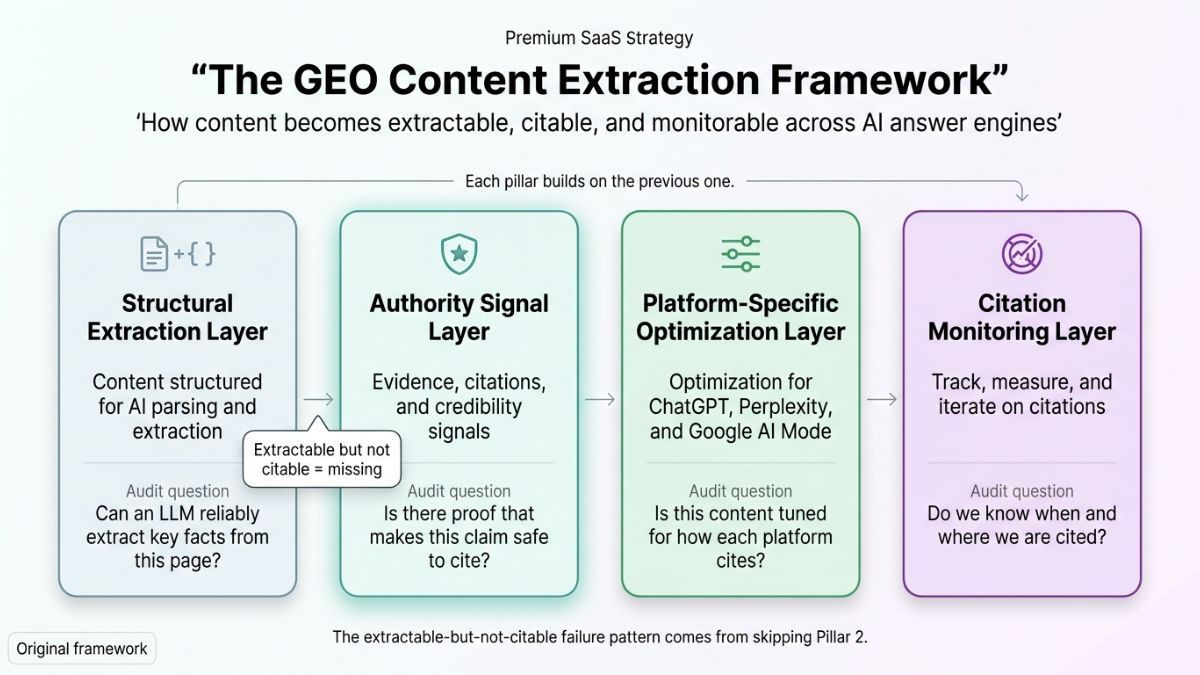
Pillar 1 — Structural Extraction Layer
Content architecture designed for passage-level retrieval: direct answer paragraphs that open with the answer, FAQ blocks where each answer is complete without adjacent context, self-contained claim units that deliver meaning independently. This is the floor of GEO readiness. It makes content extractable. It does not make it citable.
Audit question: Can any paragraph in the content stand alone as a cited passage, without requiring the reader to have read the paragraph before it?
Pillar 2 — Authority Signal Layer
Third-party validation that elevates content from extractable to citable: expert attribution, inline citations to primary research, original statistics from recognizable institutions. One fractional CMO who has studied GEO implementation has identified the organizational gap: precision beats persuasion — and most marketing teams aren't built for it yet. Content teams optimized for click-driving copy are not structured to produce citable claims. This is an operational transformation, not a formatting adjustment.
Brand entity optimization — the practice of maintaining consistent vocabulary and positioning signals across an entire digital footprint — is the brand-level expression of this pillar. If the brand is described differently in its own content, in analyst coverage, in press mentions, and in third-party reviews, the authority signal is diffuse. Consistency concentrates it — and gives ChatGPT's training data a coherent entity to build topical authority from.
Pillar 3 — Platform-Specific Optimization Layer
The same content piece, calibrated for the citation logic of the platform where the target audience searches:
- For Perplexity: prioritize recency signals, ensure recent publication dates are visible, and structure content for specific tracked queries.
- For ChatGPT: build cross-source topical authority through consistent brand presence in third-party publications and industry mentions — single-page optimization is insufficient.
- For Google AI Mode and Google AI Overviews: structured data, schema markup, and E-E-A-T signals; this platform most rewards existing Google optimization investment — while recognizing that AI Overviews and AI Mode draw from substantially different source sets.
Platform-specific optimization does not require creating new content for each platform. It requires identifying which platform a target query set primarily routes through, then calibrating the authority and structural signals of existing content accordingly.
Pillar 4 — Citation Monitoring Layer
Ongoing tracking of AI citation presence across platforms — not a one-time audit, but a repeatable methodology. This is what converts GEO from a content project into an operational discipline.
The monitoring methodology: define 20–30 target queries representing the categories where brand citation matters most. Run those queries across ChatGPT, Perplexity, and Google AI Mode monthly. For each query, record whether the brand is:
- Named directly (citable threshold reached)
- Paraphrased without attribution (extractable threshold only)
- Absent
Track citation stability across model updates — a brand appearing in month one and disappearing in month two without content changes is exhibiting the volatility pattern that requires authority layer reinforcement.
Available tools include Meridian (trymeridian.com), which tracks brand citations across ChatGPT, Google AI Overviews, and Perplexity; Otterly.ai, used by 20,000+ marketing professionals and recognized by G2 for monitoring across six AI platforms including Gemini and Copilot; and SE Ranking's AI Visibility Tracker, which includes a feature that surfaces competitor mentions where your brand is absent.
Measuring Generative Engine Optimization — The Metrics That Replace Rankings
Three measurement inputs constitute a working GEO monitoring methodology.
- Citation presence rate — the percentage of target queries on which the brand is named, not just paraphrased, across monitored platforms. This is the headline metric; it tells teams whether the citable threshold is being reached.
- Citation threshold level — for each query where the brand appears, whether it is named and attributed or only paraphrased. This is the diagnostic metric — it identifies which content has reached extractable status but not citable status, and prioritizes where Pillar 2 investment is needed most.
- Citation stability — whether presence holds across model updates or collapses within two to four weeks. This is the health metric — it distinguishes durable citation equity from fragile structural presence.
AI citation is not a traffic metric. It is a brand perception metric. As Buddle put it: "Influence now precedes traffic." The measurement question is not "how much traffic did AI send us" — it is "is our brand present in the AI-generated answers shaping buyer awareness before any click occurs?"
That framing is a strategic argument as much as a technical one. GEO measurement belongs in the brand monitoring stack, not only in the SEO reporting stack. A CMO does not need to understand retrieval architecture to understand that buyers are receiving AI-generated answers to their category questions — and that those answers may or may not include the brand.
GEO in 2026 — Build Citation Equity Before the Gap Is Visible
The brand absent from the ChatGPT answer despite ranking #3 in Google has a specific, diagnosable problem: it reached the extractable threshold and failed the citable threshold on the platforms that matter for that query. The fix is not better rankings. It is third-party validation signals — expert attribution, inline citations, original statistics from external sources — combined with cross-source brand presence that gives ChatGPT's training data something to build topical authority from.
The platform comparison is what makes the prescription specific. Perplexity's recency bias means content that earned citations six months ago may now lose to a more recently published, less authoritative source. Google AI Mode's E-E-A-T weighting means structured data investments that don't move Perplexity citations are doing real work elsewhere. The KDD 2024 GEO research shows these are not marginal differences: expert quotes, inline citations, and statistics each produced 30–40% visibility lifts in controlled experiments, while keyword stuffing performed below baseline — representing the gap between a brand that is cited and one that isn't on a platform now shaping buyer perception before any Google search occurs.

The monitoring methodology is what makes the strategy durable. Model re-ranking is continuous and silent. Brands go from cited to absent after a single update with no warning, no ranking change, and no signal in existing reporting — the pattern Profound and Otterly.ai have documented across tracked brands in their monitoring data. Citation equity, tracked monthly across a defined query set, is the early warning system no ranking report can replace.
Generative engine optimization in 2026 is not a future-state initiative. Zero-click AI answers — responses that form buyer impressions without a search click ever occurring — are already the default experience on ChatGPT and increasingly on Google. The brands building citation equity now are accumulating an advantage that compounds silently, in the same way citation gaps are accumulating silently for the brands that aren't.
GEO isn't the next SEO. It's the operating model for a world where your buyer's first impression of your brand is formed by an AI that may never send you the traffic to prove it happened.
Frequently Asked Questions
What is generative engine optimization (GEO)?
Generative engine optimization is the practice of making content citable — not just crawlable — by AI systems including ChatGPT, Perplexity, and Google AI Mode. Unlike SEO, which optimizes for search ranking visibility, GEO optimizes for selection: being the source an AI trusts enough to name in a generated answer. It requires structural, authority, and platform-specific signals.
How is GEO different from SEO?
SEO optimizes for visibility — appearing in more search queries. GEO optimizes for selection — being cited by name in an AI-generated answer. The platforms are architecturally distinct: ChatGPT tends to weight cross-source brand authority, Perplexity weights recency, and Google AI Mode weights E-E-A-T signals. A single unified strategy will tend to underperform on at least two of the three.
Why does my content rank in Google but not get cited by ChatGPT?
Google ranking and ChatGPT citation measure different things. ChatGPT tends to weight topical authority built through consistent brand presence across third-party sources — not individual page quality. A brand that ranks highly in Google but appears in few external publications, analyst mentions, or peer reviews may have strong Google visibility and near-zero ChatGPT citation presence simultaneously.
What signals most improve AI citation probability?
Research published at KDD 2024 by a multi-institution team (Princeton, Georgia Tech, The Allen Institute for AI, and IIT Delhi) found that methods involving expert quotes, statistics, and inline citations to primary sources each produced 30–40% visibility improvements, with the best-performing method achieving a 41% lift. Keyword stuffing — a legacy SEO tactic — performed below baseline. The highest-impact signals are authority-level, not structural: third-party validation that AI systems can cross-reference before surfacing a source.
How do you measure GEO performance without a rankings report?
Track three metrics monthly across a defined set of 20–30 target queries: citation presence rate (percentage of queries where the brand is named, not paraphrased), citation threshold level (named vs. paraphrased for each appearance), and citation stability (whether presence holds across model updates). Tools including Meridian, Otterly.ai, and SE Ranking's AI Visibility Tracker support this methodology.
